进阶篇-为小白设计的电池教程
版权©️声明 : 本文章神楽小白(GZ小白)的部落阁
为小白设计的电池教程(DSDT)
编写者:G.Z.小白
这个教程会尽量写的简单,只要你认真,你绝对看得懂! http://bbs.pcbeta.com/viewthread-1751487-1-1.html
初步了解 实现原理 : 由于苹果无法使用ACPI EC中超过8位的寄存器(又叫EC缓冲区,Embedded Controller Buffer ),我们需要利用Hotpatch的原理更名涉及到EC的Method使其失效并在新建的SSDT补丁中重新定义它们,使macOS能够通过SMC电池驱动正确识别电池EC信息。
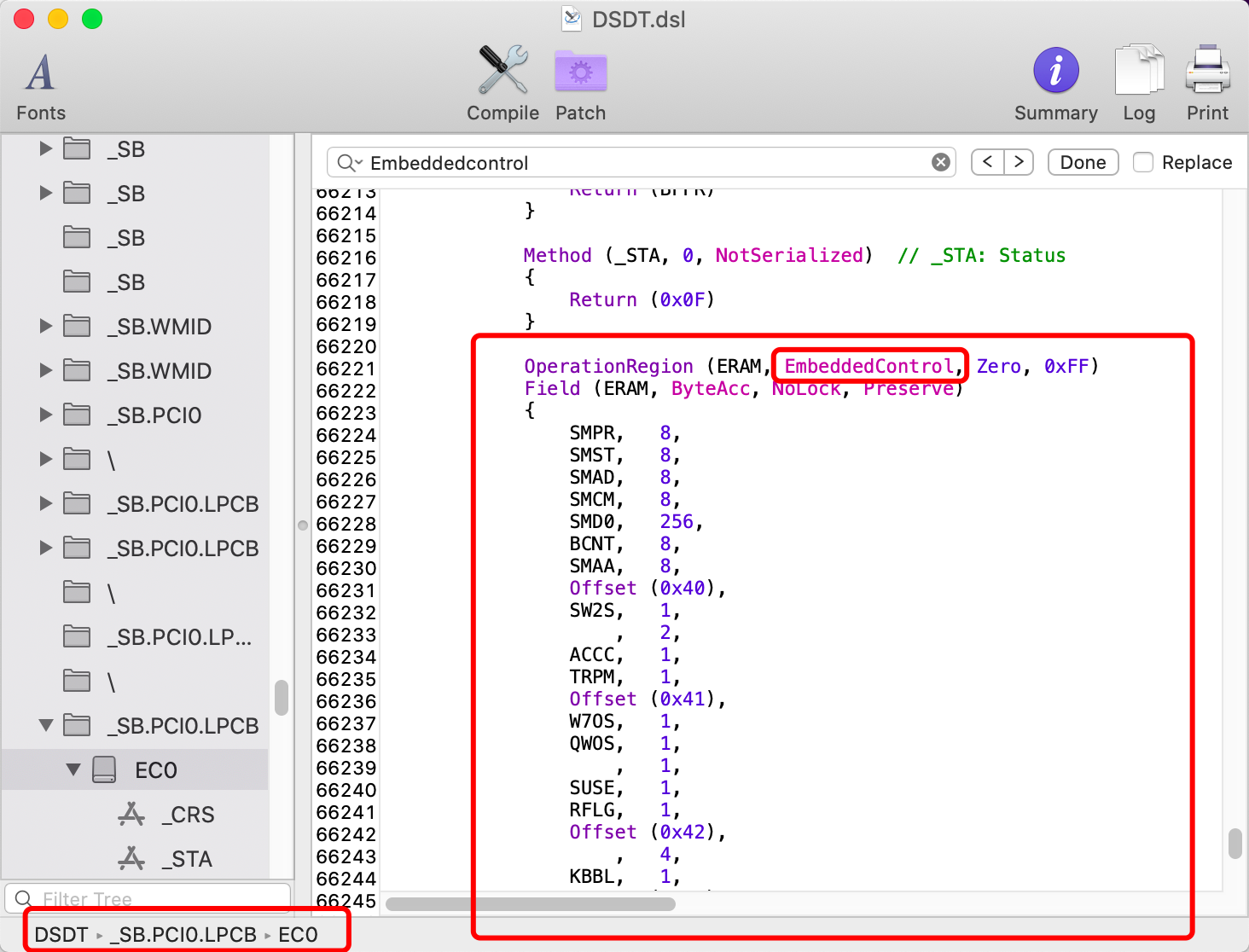
好了,我觉得你应该得有个可以用的DSDT 吧,如果没有请去提取自己的DSDT并反编译,排好错。具体见群文件的教程。Embeddedcontrol
OperationRegion名称,此为EC操作区 的名称,一般名称为ERAM、ECF2、ECF3、ECOR 等,并且有的机器可能不止一个
好了现在,我们找到了这里,仔细观察,发现它在EC0控制器下,具体路径是_SB.PCI0.LPCB.EC0。当然每个人的可能不一样,最后的EC0,还可能是ECDV、EC、H_EC。8位以上 的就行(就是右边的数字)。因为电池驱动无法处理8位以上的字节,所以就需要我们手动来处理来。计算器(Mac自带) ,Maciasl ,新建一个txt文件 。
打开txt文件,我们先把一下代码复制进去(我会把这个做成样例放在群文件 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 # created by GZxioabai # add method B1B2 into method label B1B2 remove_entry; into definitionblock code_regex . insert begin Method (B1B2, 2, NotSerialized)\n {\n Return(Or(Arg0, ShiftLeft(Arg1, 8)))\n }\n end; # add method B1B4 into method label B1B4 remove_entry; into definitionblock code_regex . insert begin Method (B1B4, 4, NotSerialized)\n {\n Store(Arg3, Local0)\n Or(Arg2, ShiftLeft(Local0, 8), Local0)\n Or(Arg1, ShiftLeft(Local0, 8), Local0)\n Or(Arg0, ShiftLeft(Local0, 8), Local0)\n Return(Local0)\n }\n end; # add utility methods to read/write buffers from/to \_SB.PCI0.LPCB.EC0 into method label RE1B parent_label \_SB.PCI0.LPCB.EC0 remove_entry; into method label RECB parent_label \_SB.PCI0.LPCB.EC0 remove_entry; into Device label EC0 insert begin Method (RE1B, 1, NotSerialized)\n {\n OperationRegion(ERAM, EmbeddedControl, Arg0, 1)\n Field(ERAM, ByteAcc, NoLock, Preserve) { BYTE, 8 }\n Return(BYTE)\n }\n Method (RECB, 2, Serialized)\n // Arg0 - offset in bytes from zero-based \_SB.PCI0.LPCB.EC0\n // Arg1 - size of buffer in bits\n {\n ShiftRight(Arg1, 3, Arg1)\n Name(TEMP, Buffer(Arg1) { })\n Add(Arg0, Arg1, Arg1)\n Store(0, Local0)\n While (LLess(Arg0, Arg1))\n {\n Store(RE1B(Arg0), Index(TEMP, Local0))\n Increment(Arg0)\n Increment(Local0)\n }\n Return(TEMP)\n }\n end; into method label WE1B parent_label \_SB.PCI0.LPCB.EC0 remove_entry; into method label WECB parent_label \_SB.PCI0.LPCB.EC0 remove_entry; into Device label EC0 insert begin Method (WE1B, 2, NotSerialized)\n {\n OperationRegion(ERAM, EmbeddedControl, Arg0, 1)\n Field(ERAM, ByteAcc, NoLock, Preserve) { BYTE, 8 }\n Store(Arg1, BYTE)\n }\n Method (WECB, 3, Serialized)\n // Arg0 - offset in bytes from zero-based EC\n // Arg1 - size of buffer in bits\n // Arg2 - value to write\n {\n ShiftRight(Arg1, 3, Arg1)\n Name(TEMP, Buffer(Arg1) { })\n Store(Arg2, TEMP)\n Add(Arg0, Arg1, Arg1)\n Store(0, Local0)\n While (LLess(Arg0, Arg1))\n {\n WE1B(Arg0, DerefOf(Index(TEMP, Local0)))\n Increment(Arg0)\n Increment(Local0)\n }\n }\n end;
以上的这些东西是同用的处理方法,包括B1B2(16字节处理),B1B4(32字节处理),WECB和RECB(这两个是处理32字节以上的)
16位处理方法 接下来,我们来讲讲16位如何处理。
比如我们在Field下找到的这个16位的BADC ,我们需要将它拆分掉,拆成来两个8字节 ,这样就能被电池驱动处理了。
读取操作:
我们还是先来解释一下吧,什么是读取什么是写入 ?在DSDT中常见的是下面两种语句。
Store(BADC,ENC0)
在这里,Store语句中,BADC 是读 的操作,而ENC0 是写 的操作,解释一下,就是将BADC写入到ENC0 ,所以你可几个口诀就是“左读右写
第二种语句(新):
ENC0 = BADC
在这里,就刚好相反了,这里没有了Store,但意思还是将BADC写入到ENC0 ,所以BADC 还是读 ,ENC0 还是写 。
写入操作:
Store(FB4,BADC)
在这里,Store语句中,FB4 是读 的操作,而BADC 是写 的操作,解释一下,就是将BADC写入到ENC0 ,所以你可几个口诀就是“左读右写 ”
那么其实很好理解了BADC = FB4 这个就跟上面提到的反一下
Field(声明字段)下处理补丁:into Device label EC0 code_regex BADC,\s+16, replace_matched begin DCA0,8,DCA1,8, end;
我们先来理解一下这个,
into:针对Device label:关于这个设备范围里EC0:设备的名称code_regex:匹配搜索BADC,\s+16:被搜索的代码,\s+16表示16字节replace_matched:匹配替换begin DCA0,8,DCA1,8, end:从什么什么开始,到什么什么结束,这里的意思就是,用于替换的是“DCA0,8,DCA1,8, ”
那么整句话的意思就是,
在设备EC0的范围内搜索16字节的BADC,如果有,就替换为“DCA0,8,DCA1,8,”
我们在来表示成一个处理结果:BADC, 16,----->DCA0,8,DCA1,8,被调用的地方 进行处理。BADC 在哪些地方被调用。(重要提醒:没被调用的其实不需要拆分!意思是你根本不用去管它!
被调用的字段(一般在Method下)那里,对字段进行拆分:读 的处理补丁:into method label SMTF code_regex BADC replaceall_matched begin B1B2(DCA0,DCA1) end;
解释:
into method label SMTF:针对Method为SMTF的这个范围内code_regex :匹配(搜索)BADC:被搜索的字段replace_matched:替换匹配begin B1B2(DCA0,DCA1) end:这是被替换的内容
那么总的意思就是,
在method为SMTF这个范围里面,搜索“BADC,\s+16”, ,如果有,就把它替换为“DCA0,8,DCA1,8,” 。
那么最后的处理结果是:
未处理前:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Method (SMTF, 1, NotSerialized) { If (LEqual (Arg0, Zero)) { Return (BADC) } If (LEqual (Arg0, One)) { Return (Zero) } Return (Zero) }
打了补丁之后:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Method (SMTF, 1, NotSerialized) { If (LEqual (Arg0, Zero)) { Return (B1B2 (DCA0, DCA1)) } If (LEqual (Arg0, One)) { Return (Zero) } Return (Zero) }
当然啦,这仅仅是BADC如果是读取 的时候的处理,那要是碰到写入 的时候,我们就要像下面这样处理,不能使用B1B2的方法了 Store (Arg0, BADC) (BADC是16位的情况) Store (ShiftRight(Arg0,8),DCA1) (DCA1是16位拆分后的第二个) Store (Arg0,DCA0) (DCA0是16位拆分后的第一个)
into method label SMRW code_regex Store\s\(Arg3,\sBADC\) replaceall_matched begin Store(ShiftRight(Arg3,8),DCA1)\nStore(Arg3, DCA0) end;**
其中这段文字中的\s代表的是一个空格,\n代表的是换行,也就是回车,主要的是在搜索那里,需要注意符号转义,在任何符号前都要加一个反斜杠转义,也就是加一个\
那最后的处理结果是:
打了补丁后:
1 2 Store (ShiftRight(Arg0,8),DCA1) Store (Arg0,DCA0)
32字节处理方法 32位字段的处理方法其实跟16位一样,用到的是B1B4,区别就是,16位拆除2个 ,32拆除4个 B1CH
补丁如下:into Device label EC0 code_regex B1CH,\s+16, replace_matched begin CH10,8,CH11,8,CH12,CH13 end;B1CH,32, ---—> BC0H,8,BC1H,8,BC2H,8,BC3H,8,多拆2个 ,那就不用多废话解释了。32字节基本不会有写入操作,也从未出现过 )into method label _BIF code_regex B1CH replaceall_matched begin B1B4(CH10,CH11,CH12,CH13) end;B1B4 是32位 处理方法
1 2 3 4 Method (_BIF, 0, NotSerialized) { Store (B1CH, IFCH) //未处理前 }
打了补丁后:
1 2 3 4 Method (_BIF, 0, NotSerialized) { Store (B1B4 (BC0H, BC1H, BC2H, BC3H), IFCH) //把被调用B1CH两处拆分为4个字节 }
偏移量计算 到了32位以上的字段处理,我们会使用到RECB(读) 和WECB(写) 两个处理方法RECB(0x98, 64) WECB (0x1C, 256, FB4) RECB(偏移量, 字段长度), WECB(偏移量, 字段长度,未处理前的前参数 ) WECB 中的未处理前的前参数 ,我们举个例子好理解一点Store (FB4, SMD0) SMD0 是256位的需要处理的字段 ,在这里是写入 ,那么它的前参数,顾名思义就是前面那个FB4 偏移量 了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Offset (0x04), (基地址) CMCM, 8, //0x04 CMD1, 8, //0x05 CMD2, 8, //0x06 CMD3, 8, //0x07 Offset (0x18), Offset (0x19), (基地址) SMST, 8, //0x19 MBMN, 80, //0x1A MBPN, 96, //0x24 GPB1, 8, //0x30 GPB2, 8, //0x31 GPB3, 8, //0x32 GPB4, 8, //0x33
我们看这里的,MBMN 是需要处理的80位字段 ,它的偏移量的计算就要涉及到它上面的基地址 ,我们看到了那个基地址是0x19 ,我们还可以发现它前面有个8位的SMST ,我们将8除以8,得到1,再把0x19加上这个1,最后得到了0x1A ,那么下面那个MBPN的偏移量怎么算呢,就是将前面的都加起来除以8 ,再加上基地址 ,就是8加上80得到88,除以8,等于11,转换为16进制就是B,0x19加上B,等于0x24.(注意的是,在除以8后的数字,一定要转换为16进制,再加上基地址! )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Offset (0x53), //(基地址) B0TP, 16, // 从基地址起 ,为0x53 B0VL, 16, //16,为2个字节; 计算:上一个的起始地址0x53+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x55 B0CR, 16, //16,为2个字节; 计算:上一个的起始地址0x55+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x57 B0AC, 16, //16,为2个字节; 计算:上一个的起始地址0x57+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x59 B0ME, 16, //16,为2个字节; 计算:上一个的起始地址0x59+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x5b B0RS, 16, //16,为2个字节; 计算:上一个的起始地址0x5b+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x5d B0RC, 16, //16,为2个字节; 计算:上一个的起始地址0x5d+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x5f B0FC, 16, //16,为2个字节; 计算:上一个的起始地址0x5f+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x61 B0MC, 16, //16,为2个字节; 计算:上一个的起始地址0x61+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x63 B0MV, 16, //16,为2个字节; 计算:上一个的起始地址0x63+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x65 B0ST, 16, //16,为2个字节; 计算:上一个的起始地址0x65+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x67 B0CC, 16, //16,为2个字节; 计算:上一个的起始地址0x67+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x69 B0DC, 16, //16,为2个字节; 计算:上一个的起始地址0x69+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x6b B0DV, 16, //16,为2个字节; 计算:上一个的起始地址0x6b+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x6d B0SI, 16, //16,为2个字节; 计算:上一个的起始地址0x6d+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x6f B0SN, 32, //32,为4个字节; 计算:上一个的起始地址0x6f+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x71 B0MN, 96, //96,为12个字节 计算:上一个的起始地址0x71+0x4(上一个的32位占了4个字节,10转为16进制为0x4)值为0x75 B0DN, 64, // 64,为8个字节;计算:上一个的起始地址0x75+0xc(上一个的96位占了12个字节,10转为16进制为0xc)值为0x81 B0CM, 48, // 计算:上一个的起始地址0x81+0x8(64位占了8个字节,10转为16进制为0x8)值为0x89
这里我就不说明了,自己看右边的注释理解一下吧。
1 2 3 4 5 6 7 8 9 10 Offset (0x5D), //(基地址) ENIB, 16, // 16,为2个字节; 从基地址起 ,为0x5D ENDD, 8, //8,为1个字节; 计算:上一个的起始地址0x5D+0x2(上一个的16位占了2个字节,10转为16进制为0x2)值为0x5F SMPR, 8, //8,为1个字节; 计算:上一个的起始地址0x5F+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x60 SMST, 8, //8,为1个字节; 计算:上一个的起始地址0x60+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x61 SMAD, 8, //8,为1个字节; 计算:上一个的起始地址0x61+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x62 SMCM, 8, //8,为1个字节; 计算:上一个的起始地址0x62+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x63 SMD0, 256, //256,为32个字节; 计算:上一个的起始地址0x63+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x64 BCNT, 8, //8,为1个字节; 计算:上一个的起始地址0x64+0x20(上一个的256位占了32个字节,10转为16进制为0x20)值为0x84 SMAA, 24, //8,为1个字节; 计算:上一个的起始地址0x84+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x85
举例4 最为简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Field (ERAM, ByteAcc, NoLock, Preserve) { Offset (0x04), FLD0, 64 // 64,为8个字节; 从基地址起 ,为0x04(偏移量) } Field (ERAM, ByteAcc, NoLock, Preserve) { Offset (0x04), FLD1, 128 // 128,为16个字节; 从基地址起 ,为0x04(偏移量) } Field (ERAM, ByteAcc, NoLock, Preserve) { Offset (0x04), FLD2, 192 // 192,为24个字节; 从基地址起 ,为0x04(偏移量) } Field (ERAM, ByteAcc, NoLock, Preserve) { Offset (0x04), FLD3, 256 // 256,为32个字节; 从基地址起 ,为0x04(偏移量) }
举例五 特殊:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 OperationRegion (SMBX, EmbeddedControl, 0x18, 0x28) //第三个值是起始地址 Field (SMBX, ByteAcc, NoLock, Preserve) { PRTC, 8, //8,为1个字节; 上面第三个值是起始地址0x18 SSTS, 5, //计算:上一个的起始地址0x18+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x19 , 1, ALFG, 1, CDFG, 1, //上面 5+1+1+1才凑够8位(1字节) ADDR, 8, //8,为1个字节;计算:上一个的起始地址0x19+0x1(上面 5+1+1+1才凑够8位占了1个字节,10转为16进制为0x1)值为0x19 0x1A CMDB, 8, //8,为1个字节; 计算:上一个的起始地址0x1A+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x1B BDAT, 256, //256,为32个字节;计算:上一个的起始地址0x1B+0x1(上一个的8位占了1个字节,10转为16进制为0x1)值为0x1C BCNT, 8, , 1, ALAD, 7, ALD0, 8, ALD1, 8 }
32位以上字段的处理(包括64,128,256等) 在Field下,我们需要对其进行重命名 使其失效。
into Device label EC0 code_regex (SMD0,)\s+(256) replace_matched begin SMDX,%2,//%1%2 end;
这里需要注意的是要打括号 !,还有后面的SMDX 是重命名后的结果,**%2,//%1%2**这个也是要加上的!
读取调用
Store (SMD0, FB4)
into method label MHPF code_regex SMD0 replaceall_matched begin RECB(0x1C, 256) end;Store (SMD0, FB4) —> Store (RECB (0x1C, 0x0100), FB4)
写入调用
Store (FB4, SMD0)
into method label MHPF code_regex Store\s\(FB4,\sSMD0\) replaceall_matched begin WECB(0x1C,256,FB4) end;
值得注意的是,我们这边是将整个Store语句进行了替换 ,这也是WECB 处理的不同之处。Store (FB4, SMD0) —> WECB (0x1C, 256, FB4)
Mutex确认,最后检查 确保DSDT里的Mutex 都是0x00 ,不然可能会出现电量显示0%的情况。Mutex ,如果有的不是0x00,你就自己手动改成0x00。
补充 当电池有时能正常显示电量,有时不能会出现一个小叉,则可能是多个电池的位置导致的,如图有两个位置,分别为“BAT0”和“BAT1”,我们需要禁用掉“BAT1”这个位置,以达到正常读取电量
加入博主的Hackintosh交流群:679838716